1.pls
title : ‘[PLS-SEM] 1. Partial Least Squares’ categories : ‘SEM’ tag : [‘stat’ , ‘PLS’, ‘PLS-SEM’] toc : true date : 2022-08-25 last_modified_at : 2022-08-25
PLS-SEM 에 대해 다루기 전에 PLS 자체에 대한 공부를 합니다.
내용 출처는 유튜브 김성법 인공지능공학연구소 입니다.
1. Intro
1.1. 고차원 데이터 : x변수가 많다 !
- 변수의 수가 많음 -> 불필요한 변수 존재
- 시각적으로 표현이 힘듬
- 중요한 변수를 선택하는 차원축소 과정이 필요함.
1.2. 변수선택과 변수추출
- 변수선택 : 소수의 변수를 선택하여 사용
- 변수추출 : 변수의 변환을 통해 새로운 변수 추출
- 변수간 상관관계를 고려하여 새로운 변수를 만들며, 변수의 개수를 많이 줄일 수 있음.
2. 부분최소제곱법(Partial Least squares)
- PCA는 예측변수의 선형결합의 분산을 최대화하는 변수를 추출했지만,
- PLS는 X선형결합과 Y간 공분산을 최대화하는 변수를 추출한다.
2.1. 개요
- PLS는 Y와의 공분산이 높은 k개의 선형조합 변수를 추출하는 방식
- 추출된 변수는 pca에서는 반영하지 못했던 y와의 상관관계를 반영한다는 특징이 있음.
2.2. 식
-
$t = Xw$
-
$cov(t,Y) = corr(t,Y) \sqrt{var(t)} \sqrt{var(Y)}$
-
-> $max cov(t,Y)$
-
단순 선형결합의 분산 뿐 아니라, Y와의 상관관계도 극대화함.
-
이때 $w$를 weight, $t$를 score라고 한다.
2.3. w는 어떻게 설정하는가
\(max ~cov(t,Y) = E[(xW)Y]\)
\(= \frac{1}{n} (Xw)^T Y = \frac{1}{n} w^T (X^T Y)\)
\(= ||w|| \cdot || X^T Y|| \cdot cos \theta\)
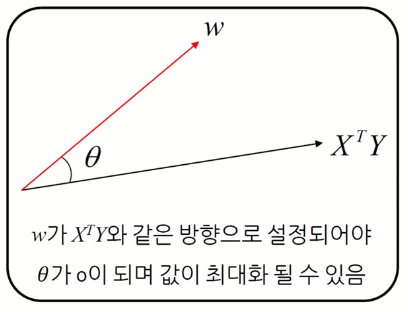
- $w$ 가 $X^T Y$ 와 같은 방향이어야 $\theta$ 가 0이 되며 값이 최대화 된다 .
- $\therefore$ $w = X^T Y$
3. NIPLAS 알고리즘
Nonlinear Iterative Partial Least Squares(NIPALS)
Step1 데이터 정규화 (mean centering)
Step2 첫번째 PLS 변수 ($t_1$) 추출
-
(1) 첫 번째 $X,Y$ 설정 : $X_1 = X,~~ Y_1 = Y$
-
(2) $ w_1 = \frac{X_1^T Y}{\vert\vert X_1^T Y\vert\vert} $
-
(3) 가중치 $w_1$ 을 활용하여 첫 번째 $PLS $변수 $t_1$ 추출
$t_1 $ = $X_1 w_1$
-
(4) $t_1$의 회귀계수 $b_1$ 을 계산
$Y_1 = t_1 b_1 + F_1$ , $b_1 = (t_1^T t_1) ^{-1} t_1^T Y_1 $
Step3 두 번째 PLS 변수 ($t_2$) 추출
-
(1) 두 번째 $Y$ 설정
$Y_2$ = $F_1$ = $Y_1 -t_1 b_1 $
-
(2) 두 번째 $X$ 설정
$X_1 = t_1 p_1^t +E_1 ,~~~p_1^T = (t_1^T t_1)^{-1} t_1^T X_1 $
$X_2 = E_1 = X_1 - t_1 p_1 ^T$
이때, $t_1p_1^T$ 를 loading이라고 한다.
Step4 위 step 1~ step3 를 $k$번 반복
Step5 충분한 PLS 변수가 추출되면, 이를 통해 예측 값을 계산
$\hat Y = \sum_{i=1} ^k t_ib_i = t_1 b_1 + t_2 b_2 + … + t_k b_k $
4. 추출 변수의 수 결정
- $k$를 순차적으로 증가시키며 예측 결과를 확인하고, 가장 좋은 예측 결과를 보이는 $k$를 선택함
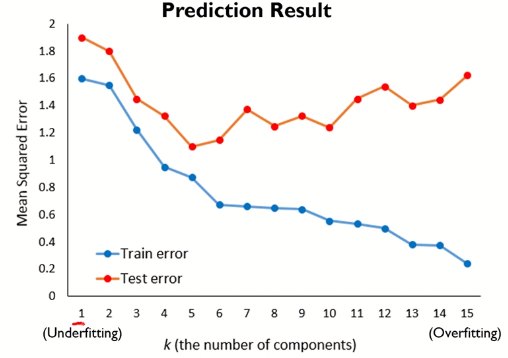
- Test error가 최소화하는 $k$ 가 가장 적합하다. (위 그림에서는 $k=5$)
Leave a comment