[EECS498]Lecture08: CNN Architecture
해당 Lecture08은 [EECS 498-007 / 598-005] 강의정리 - 8강(CS231n 9강) CNN Architectures (velog.io) 를 추가로 참고했습니다.
CNN Architecture 1
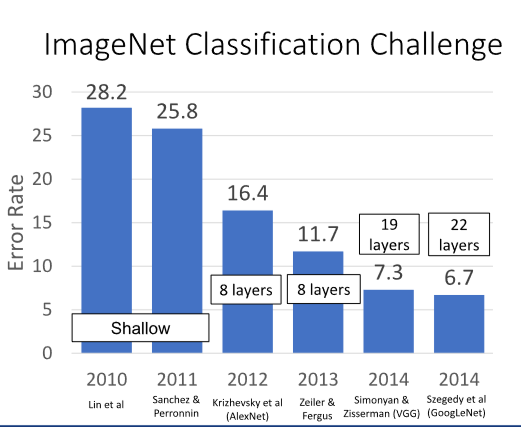
0. Imagenet Classification Challenge
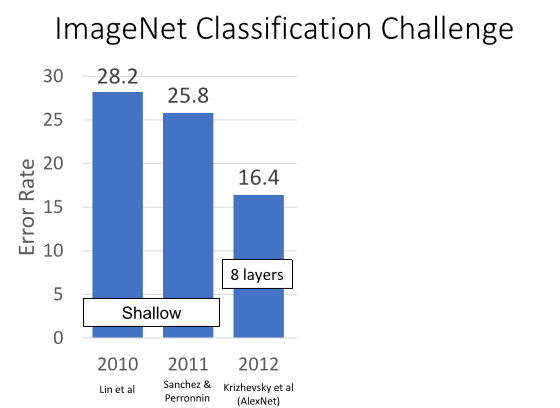
Imagenet Classification Challenge는 210년부터 ImageNet 데이터를 사용한 챌린지입니다.
1. Alexnet(2012)
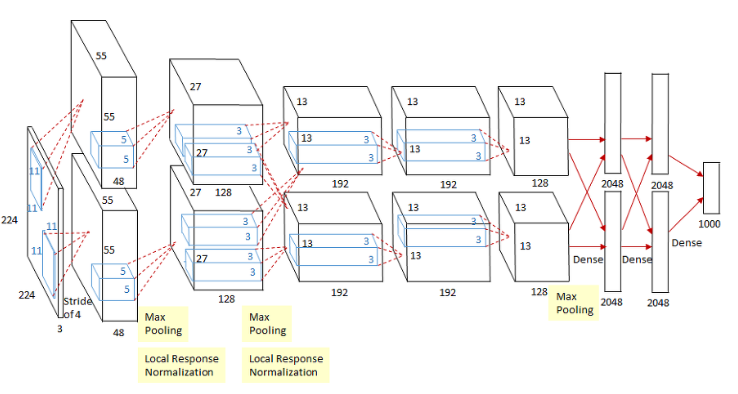
알렉스넷은 위와 같은 구조를 사용합니다.
첫번째 레이어만 학인 시,
1) model
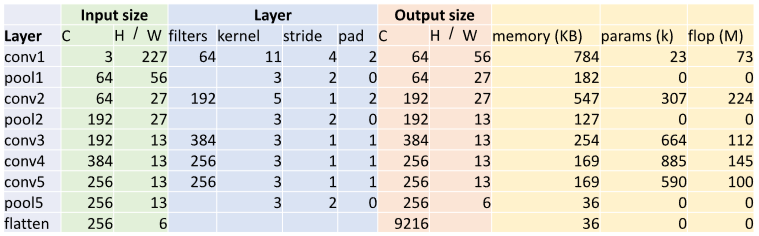
a. Output size
Input이 3channel 227x227 이미지이며 conv1은 64 filters, 11 kernel, 4stride, 2pad로 (227-11+2x2)/4+1 = 56의 output size를 가진다.
b. memory
output elemetns의 개수는 $C \times H’ \times W’$ = 64 * 56 * 56 = 200,704이다.
따라서 KB = (number of elements) * (bytes per element) /1024 = 200704 *4 /1024 = 784
c. params
number of weights = Weight shape + Bias shape
= $C_{out} \times C_{in} \times K \times K \times C_{out}$
= $64 \times 3\times11\times11\times+64 = 23,296$
2) trends
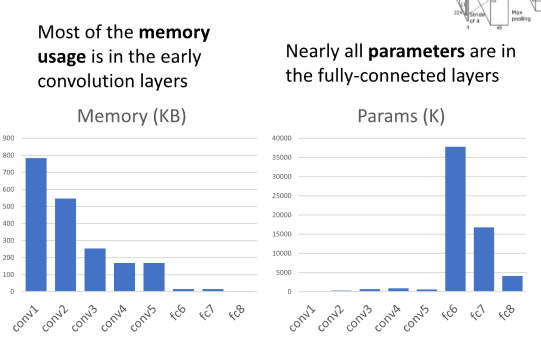
대부분의 메모리는 초반 콘볼루션 레이서에서 사용되며, 대부분의 변수는 fully-connected layer에 있다.
2. VGG
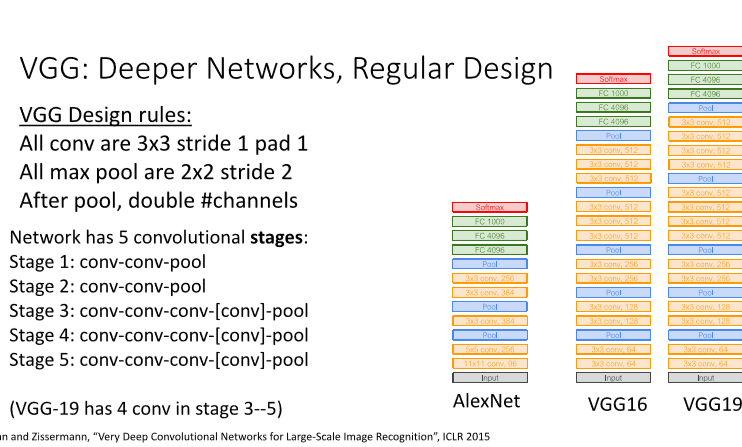
VGG는 일반화된 디자인을 가진 모델
- All conv are 3x3 stride1 pad1
- All max pools are 2x2 stride2
- After the pool, double #channels
1) model
가장 유명한 모델은 위에 나와있는 VGG16과 VGG19
2) Why VGG?
- All conv are 3x3 stride1 pad1

VGGNet은 더 적은 parameter와 더 적은 computation을 필요로 하는 양식을 제시함.
위에서 Option1과 Option2의 차이가 그것.
5x5 하나를 쌓는것보다는 3x3 두개를 쌓는게 더 좋고, 이때 param도 적게 들어가므로
더 깊은 레이어를 쌓고, 더 많은 ReLU를 넣음으로써, 더 많은 비선형성을 반영할 수 있음.
-
All max pool are 2x2 strid2 & after pool, double # channels

max pooling과 채널 수를 늘린 이후로, 파라미터 수는 4배로 늘어나지만 메모리는 오히려 반으로 줄어듬.
3. GoogleNet
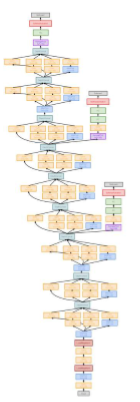
구글넷은 VGG와 같은 해에 나왔고 우승을 차지함.
크기를 키웠던 VGG 등과 달리 구글넷은 efficiency 를 늘리기 위해 노력을 많이 했다.
1) Aggressive Stem
초반 conv layers에서 계산량이 많으므로 구글넷은 초반에 input images를 매우 빠르게 다운샘플링함.
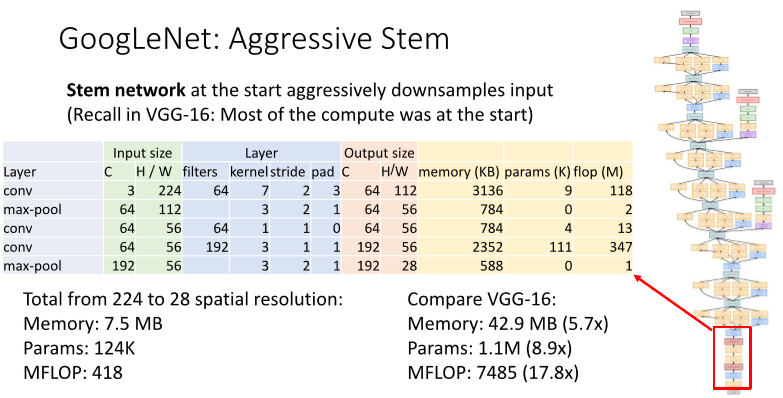
max-pooling을 초반에 넣어서 224x224짜리 이미지를 빠르게 28x28로 줄인다.
2) Inception Module
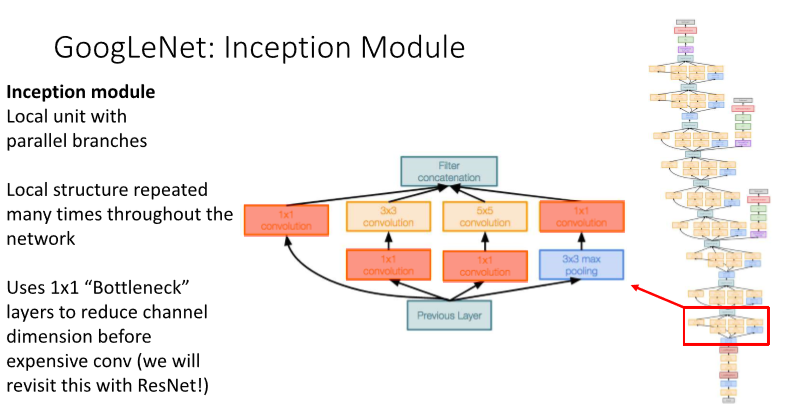
Stem 이후로는 위와 같은 Inception Module을 여러번 반복한다.
3x3를 deep하게 도입한 vgg와 다르게, 여러개의 kernel을 parallel하게 진행한다.
또한, 값비싼 conv를 사용하기 전에 1x1 “bottleneck” 레이어를 적용해 channel dimension을 줄이도록 하고 있다.
3) Global Average Pooling

마지막에 무거운 FC 레이어가 아니라 GLOBAL average pooling을 통해 진행한다.
4) Auxillarty classifiers
Batch normalization이 없던 시절, 해당 기능과 비슷한 기능을 했다.
중간 단계에 들어가, 이곳에서도 분류를 진행해 loss 생성해 계싼한다.
4. Residual Net
1) background

일반적으로 deeper model은 overfitting이 일어날 것이라 생각하지만,
nn의 레이어가 깊어질 때 트레인 에러와 테스트 에러가 동시에 하락하지만, 성능은 얕은 모델보다 더 안나오는 일종의 underfitting 문제가 발생했습니다.
즉, deeper model에서 optimize가 제대로 이루어지지 않았으므로, 이를 해결해야 했다.
문제점
deeper model은 항상 shallower model을 emulate할 수 있다. 즉, 20 layers를 복사하고 나머지를 항등함수(identity function)으로 정의하면 20 layer를 나타낼 수 있다.
가설
optimization 문제라고 생각하였다. Deeper model은 optimize하기 어렵고, 따라서 shallow model을 emulate하기 위한 항등함수를 학습하지 않는다는 것이다.
해결방법
네트워크를 변형하여 extra layers에서 더 쉽게 항등함수를 학습할 수 있게 한다.
2) solution
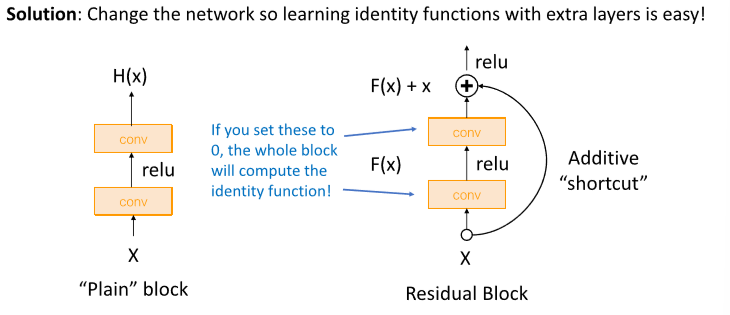
F(x)의 weight값이 0이라면 항등함수를 학습할 수 있게 된다.
3) model
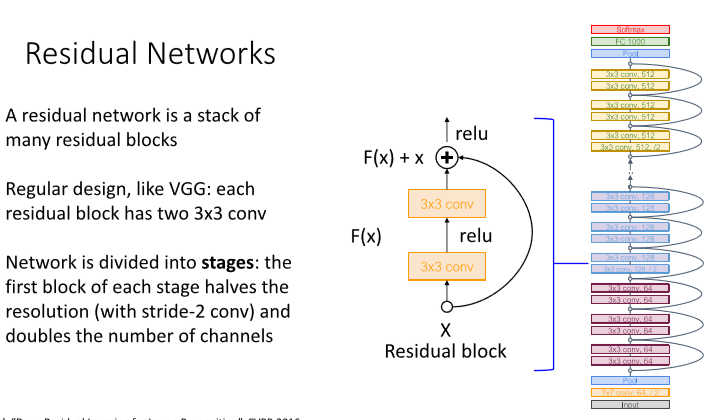
특이점은 다음과 같다.
- 각 블록에는 residual block을 적용했다.
- aggresive stem을 적용해 초반에 input을 downsampling 시킨다.
- fc layer 대신 global average pooling을 사용한다.
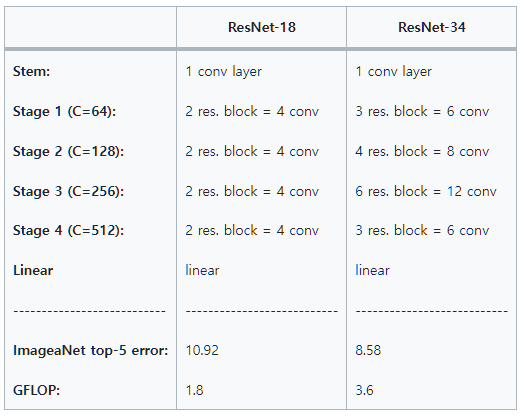
VGG-16의 ImageNet top-5 error은 9.62였고 GFLOP는 13.6이었다.
4. Bottleneck Block

깊은 모델을 형성하기 위해서는 bottleneck residual block을 이용한다. 첫번째 Conv에서 channel 수를 1/4로 줄인 다음에 3x3 Conv를 수행하고 다시 1x1 Conv를 통해 channel 수를 복구한다.
이러한 block을 사용하면 Total FLOPs는 더 적어서 적은 computation을 수행하지만 더 많은 non-linearity를 갖는다.
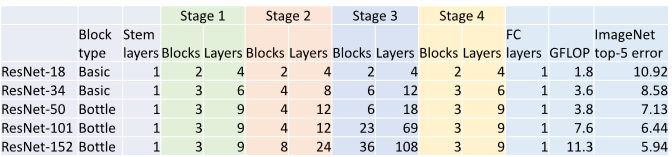
Resnet 50, 101, 152 … 는 bottleneck block을 사용하여 더 깊은 모델을 만든다.
5. Comparison
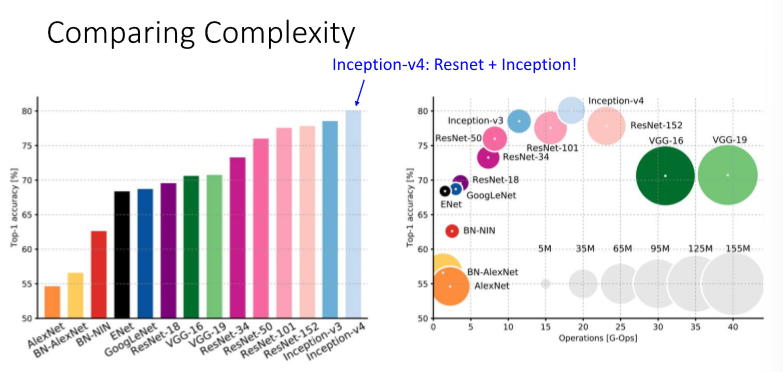
x축은 FLOPs, y축은 정확도, 원의 크기는 learnable parameters 수이다.

Leave a comment