[EECS498]Lecture10: Training Neural Networks Part2
- Distributd Training and Large-Batch Training

현실적으로 GPU를 여러가지 사용하는 방법은 똑같은 모델을 GPU마다 작동시키되, 데이터를 나눠서 각각의 GPU에 집어넣는 것이다. 각 GPU마다 각각 gradient 업데이트를 하고, grad params를 교환한다.

그러면 조금 더 큰 large-batch에 대해 training을 할 수 있고, K배 빠르게 할 수 있다!
그러면 그 방식은 어떨까?

일종의 rule of thumb 방식이지만, GPU가 k개이면 learning-rate을 k$\alpha$를 쓰면 좋다.
물론 그냥 rule of thumb이고, 논문마다 다른 수치를 제시하기도 함.
그 외에
- Model Ensembles
Model ensemble을 통해 extra score를 얻을 수 있다.
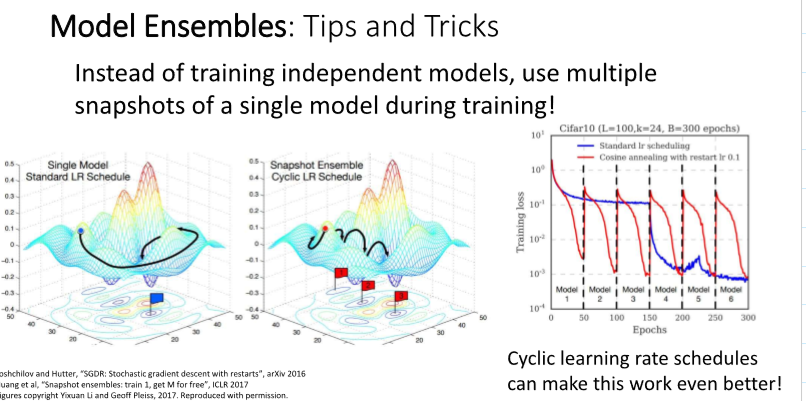
단순 결과의 가중평균도 좋지만, 위와 같은 방식도 존재한다. Learning rate을 cyclic하게 하면, 여러 모델을 훈련한 것과 비슷한 효과가 난다!

저렇게 사이클마다의 패러미터의 moving average를 테스트타임에 사용하면 일종의 앙상블 효과가 생긴다.
- Transfer learning

마지막 fc layer만 교체하면 많은 훈련없이 높은 성능을 보일 수 있다.
복잡하게 형성된 기존의 모델의 성능을 간단한 전이학습(빨간 선)으로 근접할 수 있다.

데이터만 충분하다면 fine-tuning을 하면 더 좋은 성능을 뽑을 수 있다. lr을 낮춰서 추가적인 학습을 진행하면 된다.
Leave a comment