[EECS498]Lecture13: Object detection1
1. Object Detection
1.1. definition

Single RGB 이미지에서 대상을 식별합니다. 특징으로는 ‘여러’ 대상이라는 점이고, 위의 박스와 같은 형태로 식별으르 합니다.

Object Detection은 Image classification에 비해 어려운 점이 있다.
- Multiple outputs : 한개의 이미지만 분류했던 image classfication과 달리 이미지 당 여러 종류의 objects를 감지해야한다.
- Multiple types of output: category label과 bounding box 두개의 output을 갖는다.
- Large images : 이미지 분류에서는 224x224면 충분했지만 여러 종류의 object를 감지해야하기 때문에 고해상도의 이미지를 필요로 한다. 따라서 더 많은 계산과 시간이 들어간다.
1.2. Metric
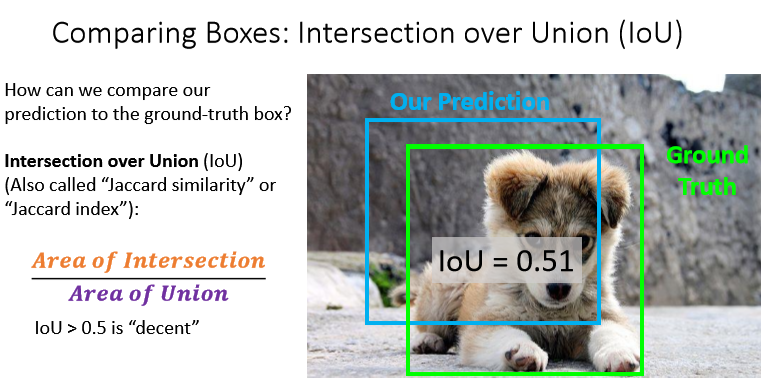
우리의 ground-truth와, model의 예측 영역이 얼마나 겹치는지를 평가지표로 삼는다!
1.3. detecting a single object
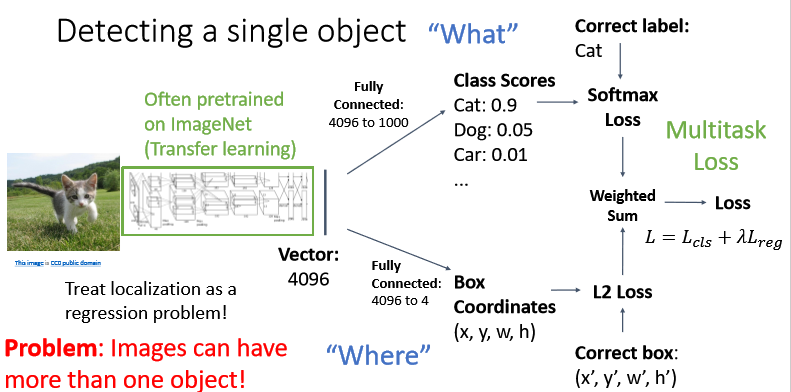
기본적으로 vgg나 resnet 등의 CNN을 통과시켜 feature vectors를 얻는다. 그리고 single object detection task에서는 2가지 task branch를 수행한다.
- 4096 → 1000 fc-layer을 통해 “What” 클래스인지 찾아낸다. 기본적인 image classification과 같다.
- 4096 → 4 fc-layer을 통해 “Where” 박스의 좌표를 찾는다. 이는
L2 Loss또는regression loss등을 사용하여 계산한다.
이렇게 하면 category label과 bounding box 두 개의 loss가 발생한다. 그러나 gradient descent를 위해 single loss가 필요하다. 따라서 이 두 loss를 weighted sum하여 final loss를 계산한다.
1.4. Detecting multiple objects : Sliding window

window를 sliding해가면서 각각에 대해 CNN을 적용한다.
그런데, 문제는 박스가 엄청 많이 필요하다는 것
박스의 크기별로, 이미지 전체를 슬라이딩 해야하므로 \(\sum\limits_{h=1}^{H}\sum\limits_{w=1}^{W} (W-w+1 )(H-h+1 ) \\ = \frac{H(H+1)} {2} \frac{W(W+1)} {2}\) 만큼의 박스가 필요한데, 이는 너무 많다.
1.5. Region Proposal
위의 문제를 해결하기 위해, 모든 오브젝트가 포함되는 regions을 찾아본다!
이미지의 모든 objects를 커버할 수 있도록 하는 영역을 찾는 것을 목표로 한다.

2. R-CNN: Region-Based CNN
R-cnn은 위의 region proposals를 위한 방법론 중 하나이다.
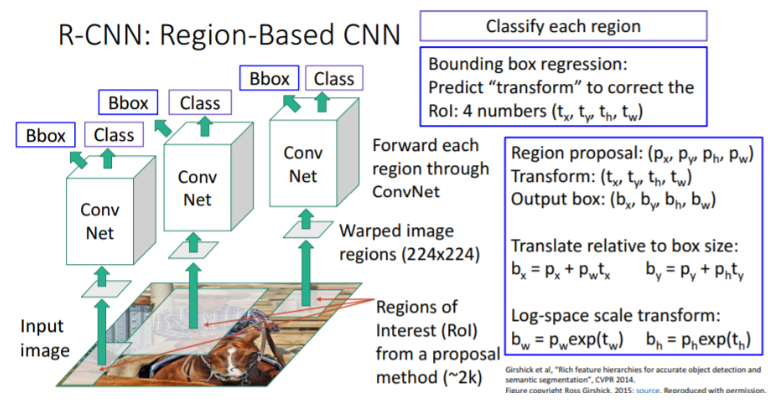
- Region propsal을 통해 region 후보들을 뽑아낸다.(약 2000개)
- 각각의 사이즈가 다르므로 224x224로 warping시킨다.
- 각각의 박스에 대해 cnn을 적용한다.
그러나 박스들이 오브젝트를 포함할 것이라는 보장이 없다. 따라서 box regression 이라는 방법을 통해 오브젝트를 포함하도록 조절한다.
2.1. Box Regression
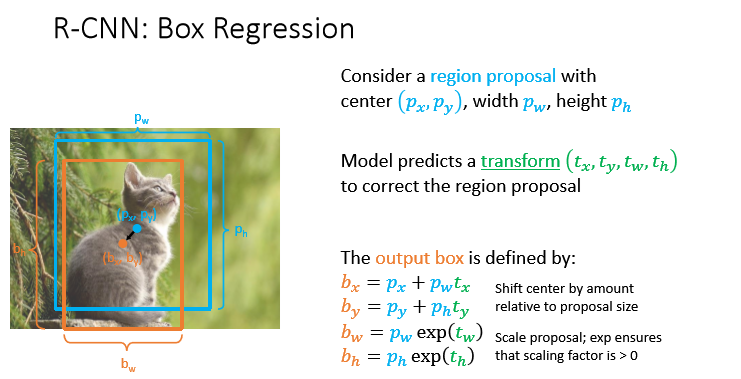
박스를 오브젝트를 포함하도록 transform 해주는 transform vector $(t_x ,t_y ,t_w ,t_h)$
를 예측한다.
그리고 이를 바탕으로 다음과 같이 output box를 만든다.
\[\begin{aligned} b_x &= p_x + p_w t_x \\\ b_y &= p_y + p_h t_y \\\ b_w &= p_w exp(t_w ) \\\ b_h &= p_h exp(y_h) \end{aligned}\]이때 $b_x , ~b_y$는 박스의 중심을 옮기는 것을 의미하고,
$b_w, b_h$는 scale을 바꾸는 것을 의미한다. $exp$ 를 넣는 이유는 스케일 조절이 $(+)$값을 가지도록 하기 위함!
2.2. Training
일련의 훈련과정은 다음과 같다.

ground-truth와의 IOU를 계산해 POSITIVE, NEGATIVE, NRUTRAL 등으로 나눈다.
렉처에서 제시하는 방안은 0.5보다 크면 Positive, 0.3보다 작으면 negative.
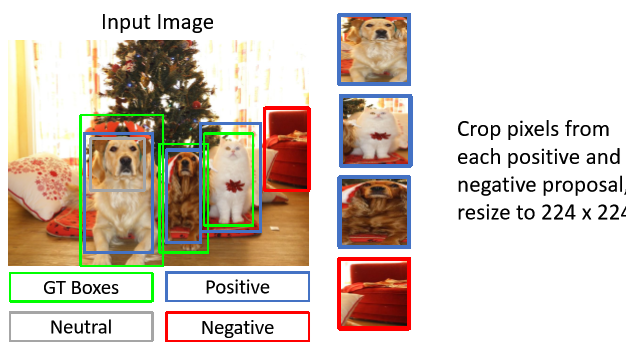
positive image와 negative image로부터 이미지를 crop하고 224x224로 변형한다.

각 region들을 cnn을 통해 훈렪나다. positive라면 class를 예측하고 transform을 하며, negative region이라면 class만 예측한다.
-
한계

2가지 한계가 있는데.
-
CNN은 중복되는 박스를 형성할 수 있다.
예를 들어, 강아지를 나타내는 박스가 2개이고 이 둘이 중복되는 것을 알 수 있음.
-
Detection 성능을 위해 threshold를 제시해야 하는데, 어떻게 찾나?
-
-
- overlapping boxes : non-max suppression
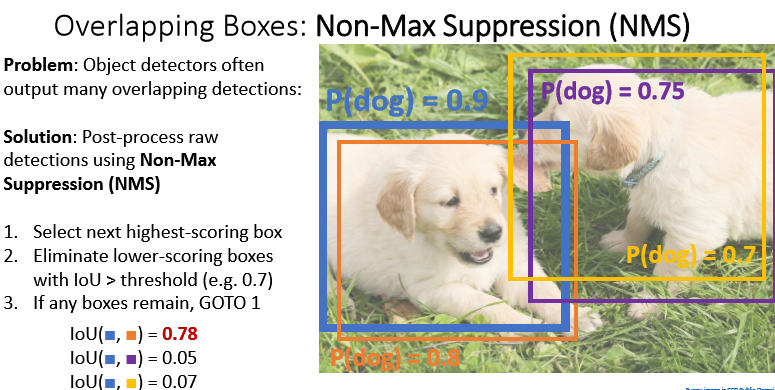
박스끼리 겹치는 경우가 많다. 이 경우, 박스간 IOT를 계산해 높은 박스는 제외할 수 있다.
- bounding box마다 classification score를 계산해서 내림차순을 정렬하고 가장 높은 score를 가진 박스를 선택한다.
- 가장 높은 스코어를 가진 박스와 다른 박스들 간의 IOU를 계산해 threshold보다 높은 값은 제거한다.
- 남아 있는 박스에 대해 1부터 다시 시작
위와 같이 score가 낮은 박스를 제거하기도 하지만, 오브젝트가 많은 경우 필요한 박스를 제거할 가능성도 있다.
2.3. mAP
-
모든 test set이미지를 가지고 object detector을 돌린다. 이때
non-max suppression을 사용하여 overlapping boxes를 제거한다. -
각각의 카테고리에 대해, average precision을 계산한다.
2.1. 각각의 detecto에 대해, IoU>0.5 라면 positive로 표시하고 GT를 제거한다.
만일 IoU < 0.5라면 negative로 표시. 그 이후, PR curve에 표시한다.
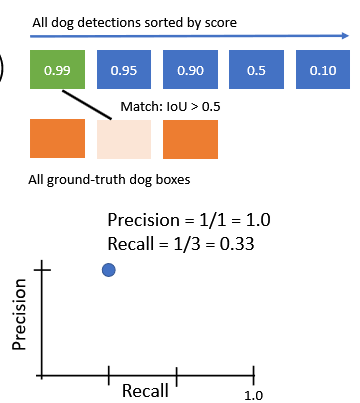
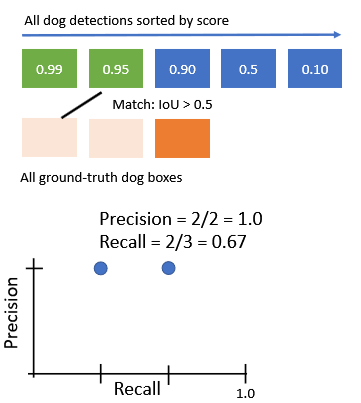
첫번째 score = 0.99에 대한 과정 진행 두번째 score = 0.95에 대한 과정 진행 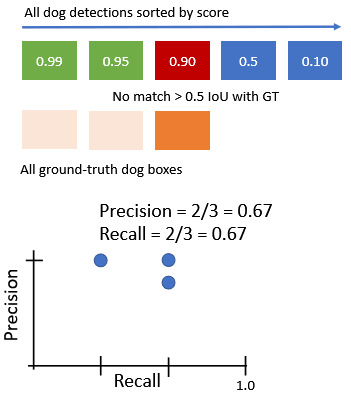
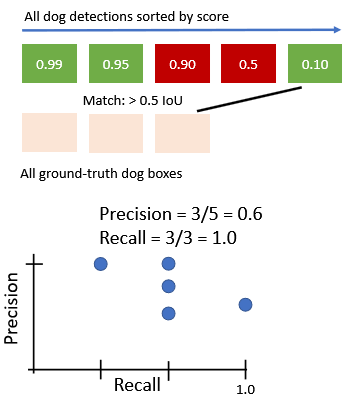
세번째 score=0.90에 대한 과정 진행 (네번째 생략) 다섯번째 score=0.1에 대한 과정 진행 2.2. PR curve 아래 영역을 area로 구한다.
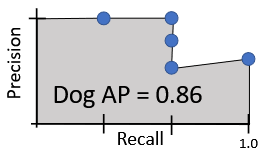
-
MAP = 각 카테고리에 대한 ap를 평균한다.
AP의 의미는 무엇일까?
AP=1.0 이라는 것은 가장 높은 scores를 갖는 detections이 모두 true positive이고, true positive를 받은 detections 사이에서 false positive는 없으며 overlapping detections(duplicate detections) 또한 없다는 의미이다(모든 detections가 GT와 대응됨).
즉, scores로 정렬된 detections에서 tp | tp | fp | tp 는 존재할 수 없다.
AP=0.0 이 될수록 안 좋은 detector이다.

Leave a comment