[EECS498]Lecture16: Redcurrent Neural Network
1. Sequential Processing of Non-Sequential Data

-
RNN은 본래 시계열 데이터 처리 방법론이다.
-
그러나, Non-Sequential data에서도 효과적으로 사용되는 경우가 있다. 여러개의 glimpse를 한 이미지에 대해 취함으로써, 다음 단계에 이미지의 어디를 볼 지 이전 단계에서 수행한 정보에 의해 정해진다.

- 위의 초록색 박스(glipse)가 이미지를 스캔하면서 훈련을 진행한다.
2. Vanilla RNN
2.1. Intro
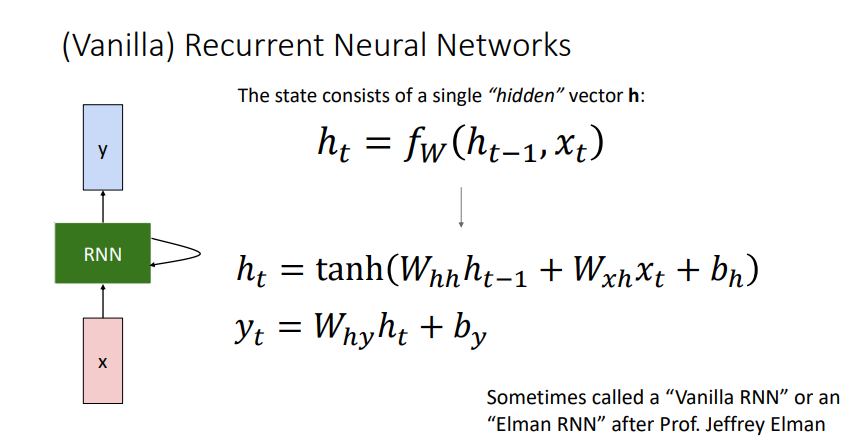
- 기본적인 RNN은 가중치 행렬 $W$를 위와 같은 함수를 통해 계산한다.
- 이때 가중치 행렬 $W$ 는 매 step마다 동일하고, 이 동일한 가중치 행렬과 함수를 매 step마다 적용한다.
- 따라서, Vanilla RNN은 위와 같이 계산된다
- $t-1$에서의 hidden state $h_{t-1}$가 $t$에서의 입력벡터 $x_{t}$에 activation function과 가중치 행렬 $W$을 적용해 $h_t$를 구한다.
- 각 step에서의 결과는 또다른 가중치 행렬 $W_{hy}$ 를 이용해 구한다.
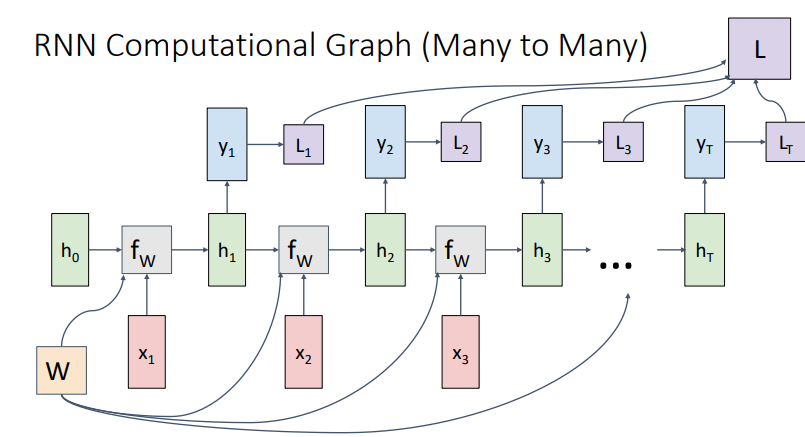
- 이런 과정을 그림으로 표현하면 위와 같다. 위의 loss function을 통해 backpropagation을 적용한다.
 |
 |
|---|---|
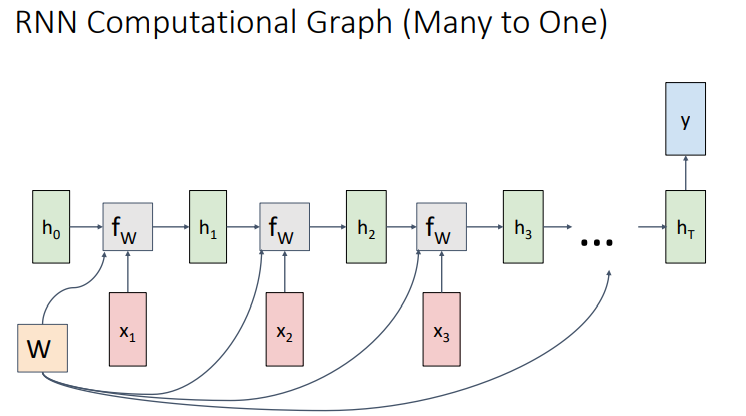
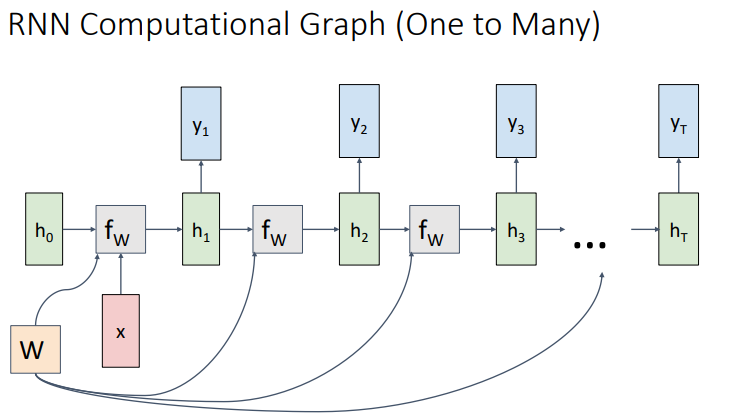
| Many to One | One to Many |
- 또 다른 경우이니 Many to One과 One to Many는 위와 같다.
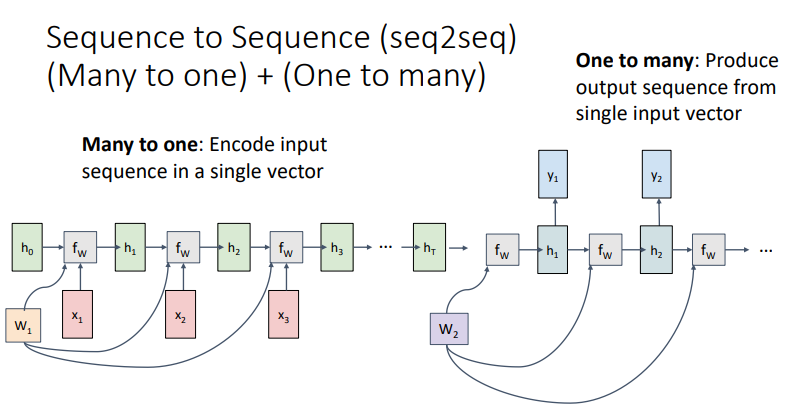
- RNN의 대표적인 예시 중 하나인 Sequency to Sequence는 위와 같이 Many to One과 One to Many의 조합으로 나타난다.
- Encoder에 해당하는 many to One RNN와 decoder에 해당하는 one to many RNN을 통해 위와 같은 형태를 가진다.
- Encoder는 입력층을 은닉층으로 embedding하며, Decoder는 이 은닉층을 바탕으로 결과를 출력한다.
- 대표적인 기계번역 방법론 중 하나!
- 이렇게 나누는 이유는 input sentence의 길이와 output sentence의 길이가 다를 수 있기 때문.
2.2. Language modelling
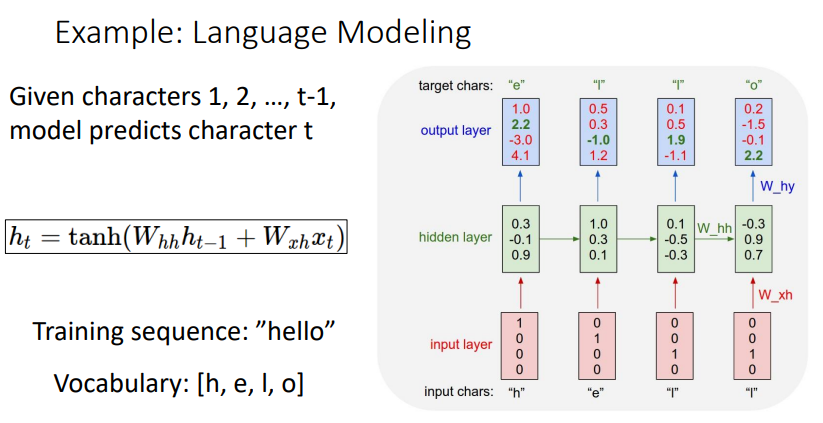
-
각 음절마다 다음 음절로 뭐가 올지 예측한다 (output layer)
즉, 각각의 입력 ‘h’,’e’,’l’,’l’에 대해, ‘e,’l’,’l’,’o’가 나오도록 예측하는 것이 목적이다.
-
hidden state을 결정하는 가중치 $W_{hh}$는 앞의 입력에 대한 정보를 이렇게 간직하면서 훈련을 진행한다.
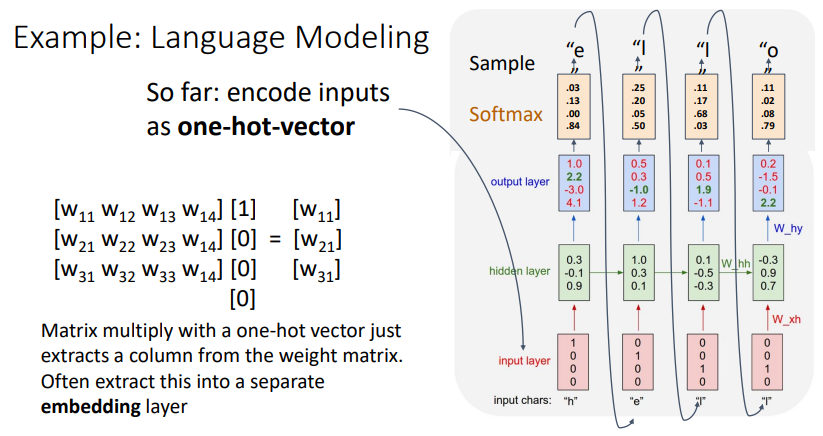
-
즉, 위와 같이 matrix multiplication을 하여 output layer를 구하고, backpropagation을 진행한다.
이때, 단순한 one-hot vector는 너무 단순한 결과를 도출하는 경우가 있으므로,
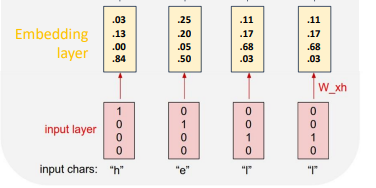
추가적으로 embedding layer를 추가하여 더 많은 정보를 이끌어내기도 한다.
2.3. Backpropagation
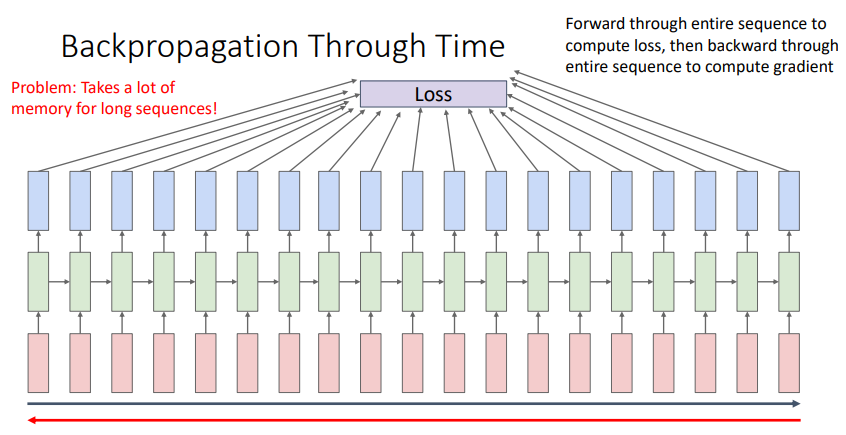
-
Sequence가 길어지면, 즉 문장이 길어지면 이 문장을 모두 메모리에 넣어야하므로 메모리가 많이 소모된다.
따라서 긴 RNN을 처리하는 경우 대체 근사 알고리즘을 사용하는데, 그 예시가 Truncated Backpropagation이다.
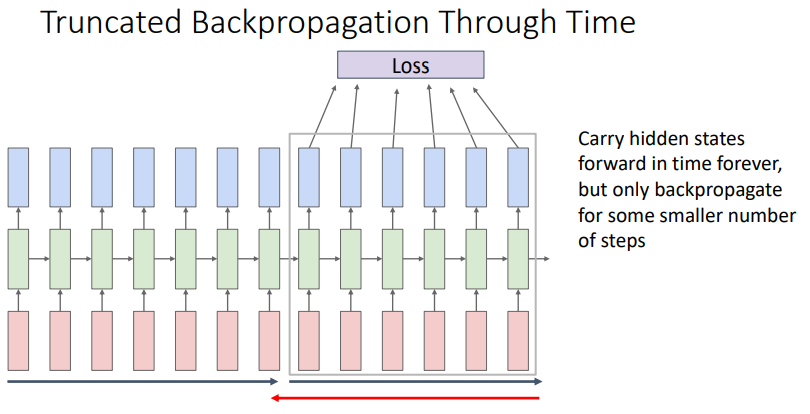
- 위의 그래프와 같이 hidden state에 대한 정보를 가져가지만, backpropagation 자체는 chunk에 대해서 진행한다.
- 첫번째 chunk의 시퀀스에서 hidden state을 구하고 loss를 구해 이 정보를 이용해 $W$를 학습한다.
- hidden state값을 기록해 두번째 chunk에 전달하고, 위의 과정을 반복한다.
- 이런 내용을 적용한 다양한 예시가 본래 렉쳐노트에 수록되어 있다. 궁금하다면 보는 것도 추천.
2.4. Searching for Interpretable Hidden Units
-
본 렉처의 강의자인 Justin Jonhson은 language model이 무엇을 학습하는지에 관한 내용을 쓴 적이 있다. 과정은 어찌보면 간단한데, RNN학습 이후 predict를 하면서 hidden state vector이 tanh을 통해 출력하는 수치는 색깔로 표시하여, 색깔이 찐할 수록 hidden state이 학습을 많이 했다는 점을 확인했다.
-
몇가지 그림이 제시되면, 빨갈수록 학습을 1에 가까운 값, 파랄수록 -1에 가까운 값을 의미한다.



- 다음 문자를 예측하는 RNN을 통해, 위와 같이 여러 hidden state vector가 각기 다른 정보를 학습함을 확인할 수 있었다.
2.5. Image Captioning
- CV 과목인 만큼, 이미지 처리에 RNN을 활용하는 Image captioning에 대해 알아보자.
- CNN과 RNN을 결합한 방법에 대해 설명한다.
-
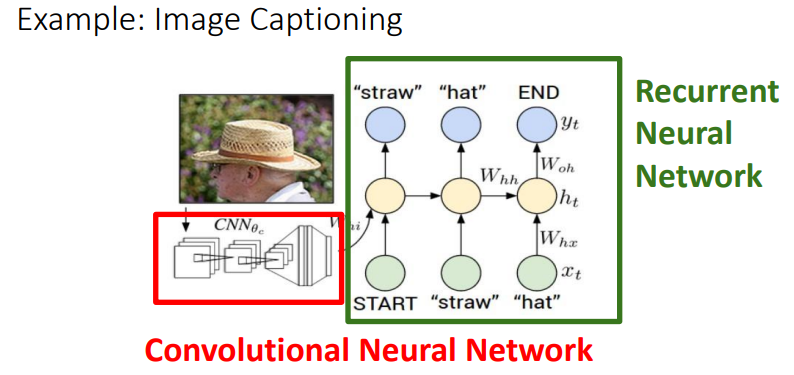
- 위의 그림과 같이, 먼저 CNN모델을 통해 feature vector를 생성하고 이후 RNN을 진행한다.
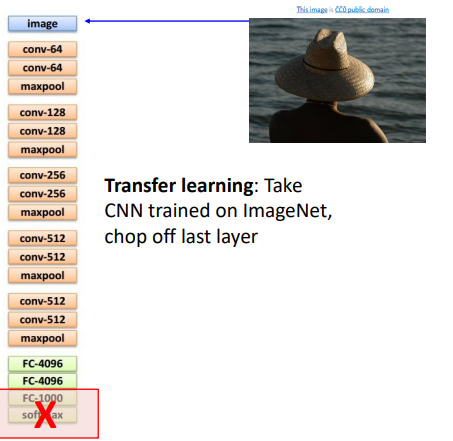
- transfer learning으로, CNN을 진행하되 마지막 레이어들을 제거한다.
- 이때, CNN을 앞에서 시행하므로 모형이 기존의 RNN과는 달라지게 된다.
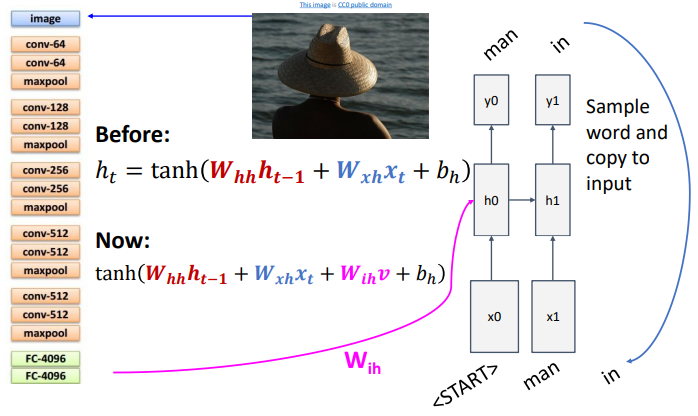
- 기존의 모델에 CNN의 결과 출력층을 추가로 반영하는데, 이때 가중치 함수 $W_{ih}$를 곱하여 반영한다.
- ‘start’로 지목된 token에서 시작하여, 위의 변형된 식을 이용해 forward propagation을 진행한다.
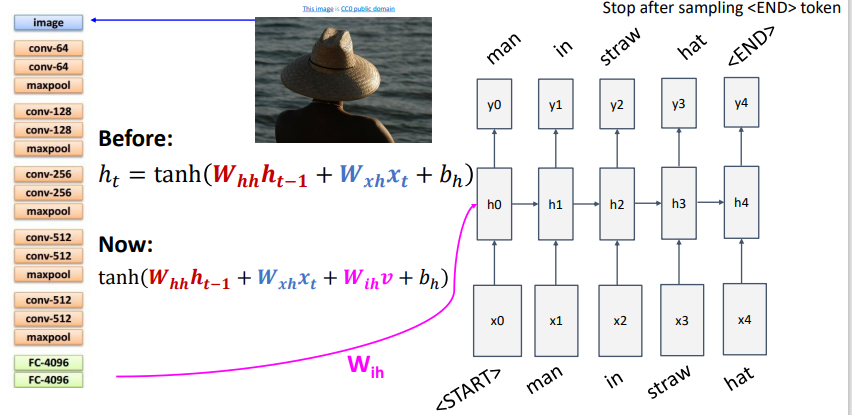
- 이런 trainninig은 ‘end’토큰에서 끝난다.
결과적으로,

위와 같이 성공적인 경우도 있지만,

- 위와 같이 실패하는 경우도 많기 때문에 image captioning model을 무작정 신뢰하기는 힘들다.
3. LSTM
3.1. Vanilla RNN Gradient Flow
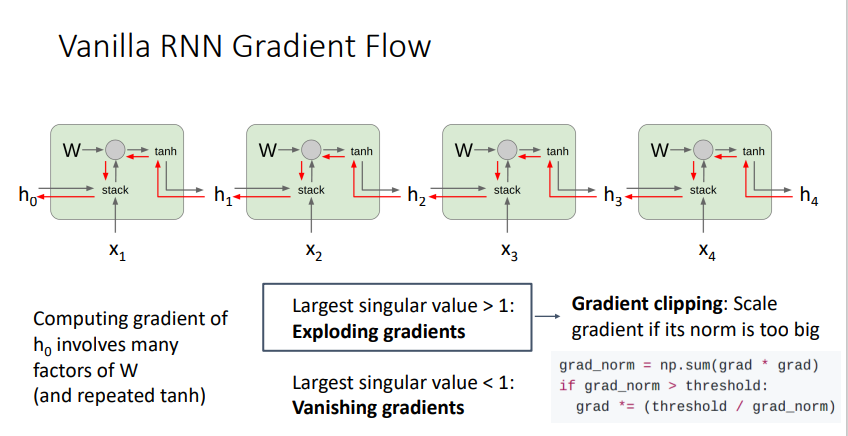
-
RNN의 경우 W를 계속하여 곱하기 때문에,
-
singular value > 1 : Exploding Gradients
-
singular value < 1 : Vanishing Gradients
두 경우 가 발생하고, singlar value = 1 인 경우에만 gradient에 문제가 발생하지 않는다. 즉, sequence가 길어지면 현실적으로 제대로 된 훈련이 불가능하다.
3.2. Long Short Term Memory
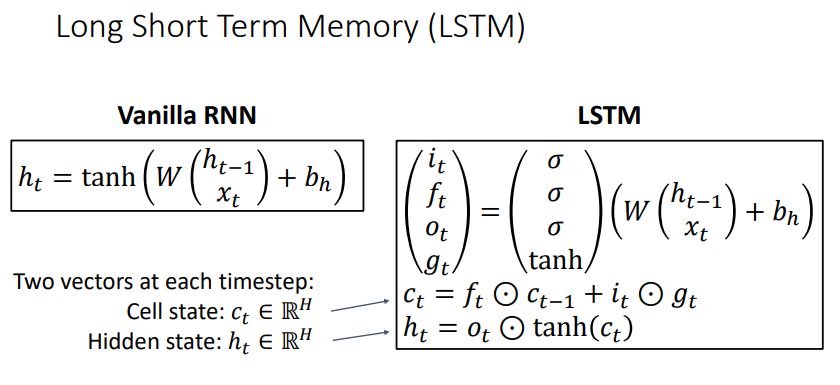
- LSTM과 Vanilla RNN의 가장 큰 차이는, LSTM은 기본적으로 두개의 hidden state을 사용한다.
- $C_t$ : cell state
- $h_t$ : hidden state
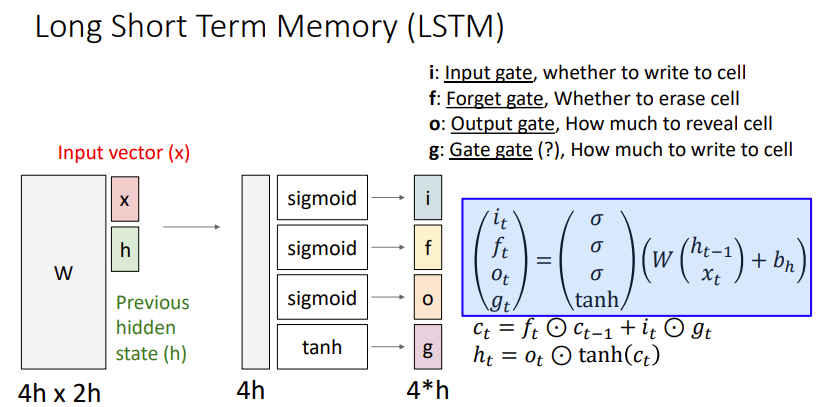
- 또한, 위의 그림과 같이 총 4개의 gate를 매 timestep마다 계산한다.
- 즉, RNN에서는 $tanh(X_t W_{hx} +h_{t-1} W_{hh}+b)=h_t$ 로 $h_t$ 만을 계산하지만, LSTM은 총 4개의 게이트를 계산한다.
-
$i$ : input gate whether to write to cell 0~1 -
$f$ : forget gate whether to erase cell 0~1 -
$o$ : output gate how much to reveal cell 0~1 -
$g$ : gate gate how much to write to cell -1~1
-
각각의 게이트를 통해 $c_t$를 계산한 그림 내 식의 의미는 다음과 같다.
-
$f_t \odot c_{t-1}$ ($\odot$ = element-wise multiplication)
cell state을 다음 단계로 넘길 지 ($f_t $ 가 forget gate이므로!)
-
$i_t \odot g_t$
gate gate은 -1~1의 값을 의미하며, 덧셈 or 뺄셈을 의미.
즉, cell state에 어떤 값을 처리하고 싶은가로 해석한다.
-
-
$h_t$
- $o_t$ 를 곱하여, 내부적으로 계산된 $c_t $를 output으로 얼마나 내보낼 지 결정한다.
3.3. Gradient flow
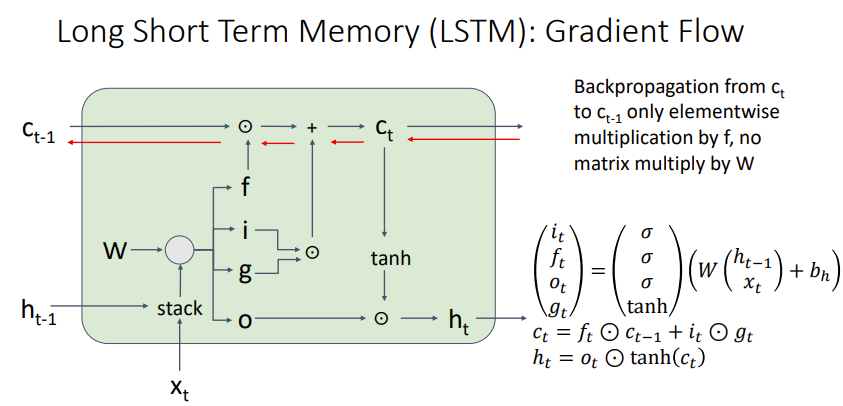
- Backpropagation에서 RNN과 차이가 발생하는 결정적인 부분은, $c_t$를 계산함에 있어 $W$를 사용하지 않는다는 것이다. 따라서, $c_t $ 가 따로 계산되고, $c_t$가 어떤 값을 주느냐에 따라 gradient를 가져갈 지, 없앨 지 결정이 된다.
- 이때 $c_t $는 0~1사이의 값과의 elementwise multiplication로만 이루어져있으므로 과정을 거침에 따라 gradient가 explode하거나, vanish하는 문제가 많이 감소한다.
###
Leave a comment