[Paper Review] UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONALGENERATIVE ADVERSARIAL NETWORKS
Review of paper, with code from PyTorch DCGAN tutorial & modificaton.
1. Intro
-
2014년 GAN 논문이 발표된 이후, 여러 연구가 진행됐지만 학습의 불안정성이 항상 문제로 제기되어 왔다. 이론적으로 GAN은 $p_{data}$를 갖는다는 사실은 증명됐지만, 실제로는 그런 결과를 거두지 못했다.
-
DCGAN은 Convolutional layer을 도입했고, 대부분 상황에서 안정적인 모습을 보였다.
-
지도학습에서는 우수한 성능을 보였지만, 비지도 학습에서는 그러지 못한 경우가 ..
4가지 컨트리뷰샨
- CNN을 이용해 GAN의 성능을 끌어올리려는 시도는 많았고, LAPGAN( Denton et al, 2015)가 그 예시이다. 그러나 성공적이지 못했다.
- extensive exploration of model을 통해 high-resolution을 끌어낼 수 있는 구조를 만들었따.
- propose and evaluate a set of constraints on the architectural topology of convolutional gans that make them stable to train in most settings.
- use the trained discriminators for image classification tasks, showing competitive performance with other unsupervised algorithms.
-
visualize the filters learned by GANs and empirically show that specific filters have learned to draw specific objects
- generators have interesting vector arithmetic properties allowing for easy manipulation of many semantic qualities of generated samples.
2. model architecture
모델의 핵심은 다음과 같음.(core of model)

Example figure:
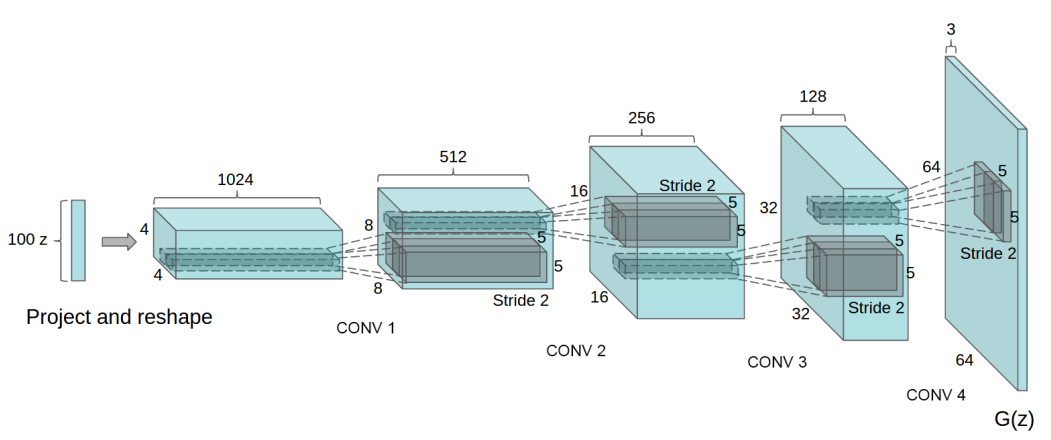
- No pre-processing except for tanh activation function [-1,1] for scaling
- SGD with mini-batches 128
- Weights initialised with standard deviation 0.02
- in the leaky ReLU, the slope of the leak was set to 0.2 in all models.
- Adam optimizer with tuned hyperparameters, 0.0002 as learning rate, $\beta = 0.5$
Fully layer is applied only once for generator, at first time when changing 100(z) shape. After this, the author used strided convolution to increase the size of feature map.
2.1. Generator
# Batch size during training
batch_size = 128
# Spatial size of training images. All images will be resized to this
# size using a transformer.
image_size = 64
# Number of channels in the training images. For color images this is 3
nc = 3
# Size of z latent vector (i.e. size of generator input)
nz = 100
# Size of feature maps in generator
ngf = 64
# Size of feature maps in discriminator
ndf = 64
# Number of training epochs
num_epochs = 5
# Learning rate for optimizers
lr = 0.0002
# Beta1 hyperparam for Adam optimizers
beta1 = 0.5
# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
The generator, $G$, is designed to map the latent space vector ($z$) to data-space. Since our data are images, converting $z$ to data-space means ultimately creating an RGB image with the same size as the training images (i.e. 3x64x64). In practice, this is accomplished through a series of strided two-dimensional convolutional transpose layers, each paired with a 2d batch norm layer and a relu activation. The output of the generator is fed through a tanh function to return it to the input data range of [−1,1]. It is worth noting the existence of the batch norm functions after the conv-transpose layers a, as this is a critical contribution of the DCGAN paper. These layers help with the flow of gradients during training. An image of the generator from the DCGAN paper is shown below
2.2. Discriminator
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
Discriminator is normal CNN layer. As mentioned, the discriminator, $D$, is a binary classification network that takes an image as input and outputs a scalar probability that the input image is real (as opposed to fake). Here, 𝐷D takes a 3x64x64 input image, processes it through a series of Conv2d, BatchNorm2d, and LeakyReLU layers, and outputs the final probability through a Sigmoid activation function. This architecture can be extended with more layers if necessary for the problem, but there is significance to the use of the strided convolution, BatchNorm, and LeakyReLUs. The DCGAN paper mentions it is a good practice to use strided convolution rather than pooling to downsample because it lets the network learn its own pooling function. Also batch norm and leaky relu functions promote healthy gradient flow which is critical for the learning process of both $G$ and $D$.
3. Data
3.1. LSUN
| ([LSUN bedroom scene 20% sample | Kaggle](https://www.kaggle.com/datasets/jhoward/lsun_bedroom?resource=download)) is a good option. |
If one can get a good resolution image by just mimicking training images, we cannot say the model is producing good images. The author applied deduplication to prevent memorization, Also removing similar beds images by autoencoder.
3.2. Celeba
(CelebA Dataset (cuhk.edu.hk))
Human faces from random websites.
3.3. ImageNet
4.Empirical Validation
- Classifying cifar-10 using gans as afeature extractor
Using gan as a feature extractor is one of ways to check the quality of unsupervised learning.
Author suggest evaluating model , by using gan architecture for to extract features of data, there by increasing the use of supervised learning.
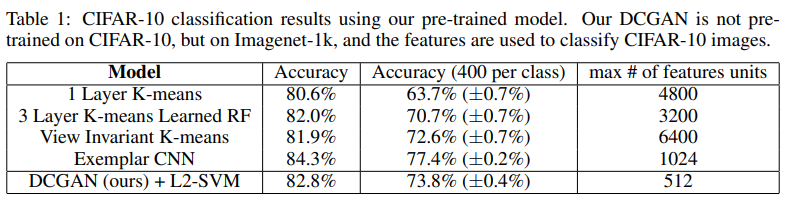
According to the author, using dcgan as a feature extactor increase accuracy of supervised model, which means that it works as a right feature extractor in the model.
5. INVESTIGATING AND VISUALIZING THE INTERNALS OF THE NETWORKS
GAN should be made sure about two parts:
-
Generator does not memorize image, it creates image (no memorization)
- Memorization means overfitting. Therefore, GAN should not be overfitted
-
Generator should produce soft image change in latent space change of variables
-
no memorization

Above image is the result of one epoch. It shows that image comes with enough quality , also since it is just one epoch, we can suppose that it is not overfitted
- soft image change in latent space vector change

Above image shows the change of image according to a little change in latent vector $z$.
It shows that Image changes softly, which means no overfitting happened here,
Also, Author shows the ‘vector arithmetic’ to suggest the visualisation of trained model,
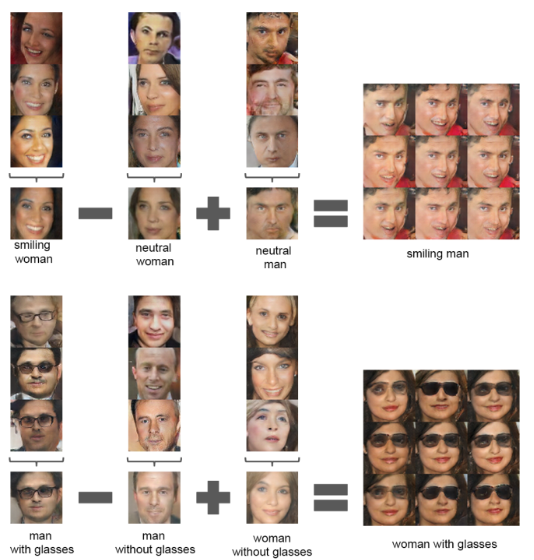
As image above suggest, man with glasses + man without glasses show woman without glasses. Which means the implicit generator train the features of image, rather than just memorizing the image.
Leave a comment