[PyTorch] 자동미분(AUTOGRAD)
PyTorch 공부하면서 중요한 내용을 기록으로 남기고자 작성합니다.
해당 내용은 A Gentle Introduction to torch.autograd — PyTorch Tutorials 1.11.0+cu102 documentation
를 참고하였습니다.
0. 배경
신경망(neural networks)은 여러 함수들의 집합체이고, 이 함수들은 PyTorch에서 Tensor의 형태로 저장되는 parameter들에 의해 정의됩니다.
이런 신경망의 학습은 전파(forward propagation)과 역전파(backward propagation)으로 구성되어있으며, 이때 역전파를 함에 있어 수차례 미분을 통한 gradients의 계산이 필요합니다.
1. 자동미분에서의 미분과정(Differentiation in Autograd)
autograd가 gradients를 모으는 과정에 대해 보자. requires_grd = True라는 옵션가 함께 형성된 두 텐서는, autograd에 신호를 보내 그들의 연산을 전부 추적하게 해줍니다.
import torch
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
위의 a와 b로 이루어진 또 다른 텐서 Q를 고려하면,
\(Q =3 a^3 -b^2\)
a와 b가 신경망의 패러미터, Q가 error라고 가정하자. 이 경우,
\(\begin{align}
\frac{\partial Q}{\partial a} = 9 a^2 \\
\frac{\partial Q}{\partial b} = -2b
\end{align}\)
만일 .backward()함수를 Q에 대해 호출한다면, autograd는 이들에 대한 gradients를 계산하고 .grad에 저장한다.
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
# check if collected gradients are correct
print(9*a**2 == a.grad)
print(-2*b == b.grad)
out:
tensor([True, True])
tensor([True, True])
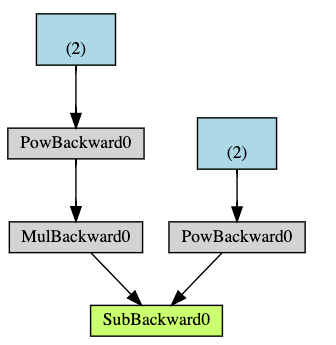
2. computational graph
autograd는 data(tensors) & all executed operations를 directed acyclic graph(DAG)에 저장한다. 해당 DAG에서 잎은 input tensor, 뿌리는 output tensor을 의미하며, 그래프의 뿌리부터 잎까지의 가지를 추적하면서 gradients를 계산할 수 있다.
-
Forward pass
-
operation을 실행하여 결과 텐서를 얻고,
-
operation의 gradient function을 DAG에 저장한다.
-
-
Backward pass
-
.grad_fn(gradient function)에서 gradients를 계산하고, -
이를 각 텐서의
.grad에 저장한다. 그리고, -
chain rule을 이용해 잎 텐서까지 propagation을 진행한다.
-
3. Exclusion from the DAG
torch.autograd는 requires_grad 가 True로 설정된 모든 텐서에 대한 연산을 추적한다. 만일 False로 설정 시 DAG 계산에서 제외된다.
NN에서 이와 같이 gradients를 계산하지 않는 변수들을 일반적으로 frozen parameters라고 불린다. 만일 어떤 변수에 대한 정보가 있고, 업데이트가 필요하지 않다면 이들을 freeze 하는게 유용할 수 있다.
바로 이런 exclusion from the DAG이 유용한 경우가 전이학습이다.
전이학습에서 finetuning을 할 때, 우리는 대부분의 변수를 freeze 한다. 간단한 예로, resnet18을 pretrained model로 불러오고 변수를 freeze 하는 경우를 예로 들자.
from torch import nn, optim
model = torchvision.models.resnet18(pretrained=True)
# Freeze all the parameters in the network
for param in model.parameters():
param.requires_grad = False
위와 같이 기존의 패러미터는 모두 freeze 하고,
model.fc = nn.Linear(512, 10)
마지막 fully connected layer만 finetunning할 수 있다.
Leave a comment