[PyTorch] DataLoader
PyTorch의 data setting에 관한 정리입니다.
[출처]
- [Datasets & DataLoaders — PyTorch Tutorials 1.11.0+cu102 documentation
- pytorch dataset 정리 · Hulk의 개인 공부용 블로그 (hulk89.github.io)
및 그 외 인터넷 소스를 참고하였습니다.
PyTorch는 data에 관해 두가지 옵션을 제공합니다.
torch.utils.data.DataLoadertorch.utils.data.Dataset
Dataset은 샘플과 해당하는 레이블을 저장하며, DataLoader는 Dataset에 대하여 iterable을 적용하여 샘플에 대한 접근을 수월하게 합니다.
0. Dataset vs DataLoader
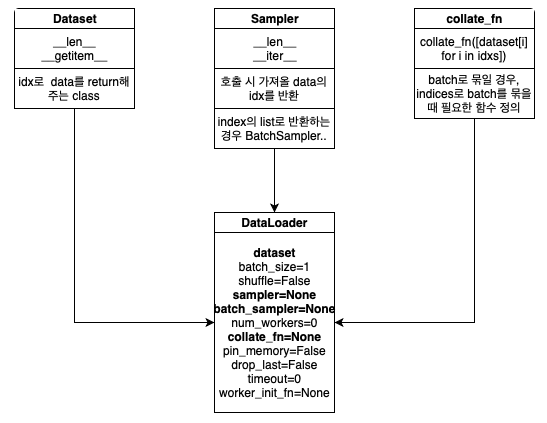
- Dataset
- Data를 가지고있는 객체.
__len__,__getitem__을 구현해야함- DataLoader를 통해 data를 받아올 수 있다.
- DataLoader
- Dataset을 인자로 받아 data를 뽑아냄
1. Loading a Dataset
pytorch가 제공하는 dataset으로 fashion-MNIST 데이터셋을 예시로 듭니다.
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
이를 시각화하면 다음과 같습니다.
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()

3. Create a Custom Dataset for your files
Dataset은 init, len, and getitem 의 세가지 함수를 갖고 있어야 합니다.
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
-
__init__init은 일반적인 class의 init과 마찬가지로, 호출 시 실행되며 이미지를 포함하는 디렉토리를 파악하고 레이블 위치 등을 읽어냅니다.
-
__len__len은 샘플의 길이를 불러옵니다.
-
__getitem__getitem은 idx에 해당하는 샘플을 데이터셋으로부터 불러옵니다. idx를 기반으로 샘플의 위치를 파악하고,
read_image를 통해 텐서로 변환하고, 연결된 labe을self.img_labels로부터 불러옵니다.
4. Preparing your data for training with DataLoaders
Dataset은 한 샘플마다 정보를 불러온다는 한계가 있습니다.
그러나, 실제 분석을 할 때는 샘플을 “미니배치” 단위로 넘기는게 일반적이고, 데이터를 reshuffle 하거나 병렬계산을 실행하는 등 복잡한 기능을 적용해야 합니다.
이런 기능들을 포함하느 API가 DataLoader입니다.
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
위와 같이 dataset을 DataLoader로 정의하면, iterate하게 기능을 적용할 수 있습니다.
아래의 함수와 같이 짤 시, iteration 마다 minibatch를 뱉어내며, 한번의 iterate 이후로는 배치가 shuffled 되도록 설정이 가능합니다!
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
Leave a comment